#2 랭체인으로 문서기반(엑셀, 구글시트, PDF) 슬랙 챗봇 만들기 Langchain Document basis Slack chatbot server like the ChatPDF (Langchain + GPT API + PDF, CSV, Google docs + Python)
But, 나의 최종 목적지는 바로 Slack Bot! 업무자동화의 끝은 봇이 아니겠는가!!
사실, 2월에 RTM(real time message) 기반으로 코드를 작성했는데 이 API가 슬랙 정책상 바뀌었다고 한다.(https://api.slack.com/rtm)
후.. 그래서 정말 이 문제를 해결하는데 많은 시간이 걸렸던 것 같다. 일단 개인pc를 서버로 사용해야하고 pc가 꺼지면 봇도 돌지 않는 문제가 있지만 뭐.. 항상 켜놓는 pc가 있으니 작업이 완료되면 옮기면 된다는 생각으로 도전해봤다.
일단 내가 겪은 문제를 설명하기 전에 내 인터넷 환경은 이렇다.
인터넷 - LG U+ 기가 인터넷 모뎀 -> LGU+ 공유기 - ASUS 공유기
-> RaspberryPi3 (Home Assistant docker 서버가 구동 중)
-> RaspberryPi4 (TelsaMate 용 docker 서버가 구동 중)
-> 지금 사용중인 랩탑과 같은 기기들
헌데 문제는 Home Assistant 를 구성하기 위해서.. 내가 사용중인 것들이 있었으니..

두둥~ DuckDNS와 Nginx Proxy Manager다.
공유기 자체 DNS를 쓰려고 했으나, LG 기가 인터넷 모뎀이 가장 끝단에서 버티고 있고 이걸 내 공유기로 대체하면 기가인터넷이 아닌게 된다고 하더라... 나에겐 기가인터넷의 빠른!! 속도가 필요했기에 중꺾마(중요한건 꺾이지 않는 마음)로 대충 어떻게 돌아가도록 구성을 해놓았다.
이게 dns를 통해서 들어온 신호들을 Nginx가 방어선을 구축하고 불필요한건 튕겨내는 구조라고 해야하나.. 8/1 수정 : 설정 문제였고 nginx와 ngrok은 동시에 구현이 가능한 것으로 확인되었다.
그러다보니, slack event subscription URL reuqest을 보내고 그 URL에 flask 서버가 화답을 해줘야 내 URL이 살아있다는 것을 캐치하고 승인을 해주는데 flask 앱으로 만든 서버로 신호를 보내도 응답이 없다는 말만 하면 실패를 거듭해왔다. 거기다가 https 여야 한다고..?으잉?!?
일단 거두 절미하고 문제와 해결법은 이렇다.
1. Nginx proxy, duckdns 사용으로 인해 flask server 로 보낸 slack event url request failed 문제
- https 문제 : 파이썬 py 파일이 있는 폴더에 가서 포트를 지정하면서 Terminal 에서 아래와 같이 입력 (나의 경우엔 Airplay 5000번 포트가 겹쳐서 5005 번으로 했다.) 여기서 main 은 py 파일의 이름이다. 바꿔서 사용하시길!
gunicorn --certfile=cert.pem --keyfile=key.pem --bind 127.0.0.1:5005 main:app
이러면 그 폴더에 cert.pem 과 key.pem 파일이 생긴다. (SSL 인증서를 발급받는 절차이다.)
그리고 파이썬 코드에서 flask app.run 부분에 아래와 같은 파라미터를 추가해준다.
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5005, ssl_context=('cert.pem', 'key.pem'))
2. Nginx 설정은 이렇게. nginx 설정 페이지로 이동한다. (아마 대부분은 이걸 안쓰실거라 ngrok으로 구동 가능하실 것으로 예상.)





from flask import Flask, request, jsonify
from flask_talisman import Talisman
import pandas as pd
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import ElasticVectorSearch, Pinecone, Weaviate, FAISS
from langchain.agents import create_pandas_dataframe_agent
from langchain.chains.question_answering import load_qa_chain
from langchain.chat_models import ChatOpenAI
from langchain.chains import AnalyzeDocumentChain
from langchain import OpenAI
from PyPDF2 import PdfReader
import os
from langchain.chains.summarize import load_summarize_chain
from slack_sdk import WebClient
from slack_sdk.errors import SlackApiError
import json
#Google docs의 경우
from google.oauth2 import service_account
from googleapiclient.discovery import build
'''
Google Docs
'''
# 서비스 계정 키 파일 경로를 지정.
SERVICE_ACCOUNT_FILE = '[본인의 Google service account file의 Path 를 적어주세요]'
# 필요한 권한 범위를 설정.
SCOPES = ['https://www.googleapis.com/auth/documents.readonly']
# 서비스 계정 키 파일을 사용하여 인증 정보를 가져옴.
creds = service_account.Credentials.from_service_account_file(SERVICE_ACCOUNT_FILE, scopes=SCOPES)
# 인증 정보를 사용하여 구글 시트 API 서비스를 생성.
service = build('docs', 'v1', credentials=creds)
# 구글 시트 ID와 범위를 지정.
document_id = 'Google Docs의 ID이다. URL에서 d/다음 /전까지의 값'
document = service.documents().get(documentId=document_id).execute()
result_doc = ""
for content in document['body']['content']:
if 'paragraph' in content:
for element in content['paragraph']['elements']:
if 'textRun' in element:
result_doc += element['textRun']['content']
# 이벤트를 추적하는 파일을 만들고. 파일이 없다면, 빈 dict를 사용.
# 이건 한 번 응답한 것을 재응답하는 것을 막기 위해서 이 방식을 썼다.processed_events.json 파일을# py 파일과 같은 디렉토리에 넣어줘야한다.
if os.path.isfile('processed_events.json'):
try:
with open('processed_events.json', 'r') as f:
processed_events = json.load(f)
except json.JSONDecodeError:
processed_events = {}
else:
processed_events = {}
# Slack API 토큰 및 채널 ID
slack_token = "슬랙토큰 자리"
slack_channel = "#슬랙채널명 자리 # 포함적어야함"
SLACK_SIGNING_SECRET = '슬랙 사이닝 시크릿 자리'
VERIFICATION_TOKEN = '슬랙 인증 토큰 자리'
# OpenAI API Key
os.environ["OPENAI_API_KEY"] = "Open AI API 유료 키 자리"
# Slack Web API 클라이언트 초기화
slack_client = WebClient(token=slack_token)
app = Flask(__name__)
Talisman(app)
# reader = PdfReader("expense_rule.pdf") # pdf
raw_text = result_doc
# # Summarize 요약
llm = OpenAI(temperature=0)
# summary_chain = load_summarize_chain(llm, chain_type="map_reduce")
# summarize_document_chain = AnalyzeDocumentChain(combine_docs_chain=summary_chain)
# summary_result = summarize_document_chain.run(raw_text)
# print(summary_result)
# Question Answering 질문 답변
model = ChatOpenAI(model="gpt-3.5-turbo") # gpt-3.5-turbo, gpt-4
qa_chain = load_qa_chain(model, chain_type="map_reduce", verbose=True)
qa_document_chain = AnalyzeDocumentChain(combine_docs_chain=qa_chain)
#엑셀, csv 검색 및 aggregation 선세팅
# df = pd.read_csv("test_members.csv")
# df.head #df.head 출력하기
# agent = create_pandas_dataframe_agent(OpenAI(temperature=0), df, verbose=True)
@app.route('/slack_events', methods=['POST'])
def process_slack_event():
# 슬랙에서 전달된 데이터 받기
data = request.get_json()
# print(data) #data 변수 디버깅용
# 슬랙 스레드 ID(ts) 및 메시지 text 추출
thread_ts = ""
thread_ts = data['event'].get('ts', None)
question = data['event']['text']
# url_verification 이벤트 처리
if data['type'] == 'url_verification':
return jsonify({'token': data['challenge']})
# 슬랙 메시지 이벤트 처리
if data['type'] == 'event_callback' and data['event']['type'] == 'message':
# If the event was triggered by the bot itself, ignore it
if 'bot_id' in data['event'] or ('subtype' in data['event'] and data['event']['subtype'] == 'bot_message'):
return jsonify({'status': 'success'})
# 'text' 키가 없는 이벤트는 무시
if question is None:
return jsonify({'status': 'success'})
# 이벤트 ID 추출
event_id = data['event']['client_msg_id']
# If event_id is None or it has already been processed, ignore it
if event_id is None or event_id in processed_events:
return jsonify({'status': 'success'})
# 새 이벤트라면, 처리하고 이벤트 ID를 저장
processed_events[event_id] = True
with open('processed_events.json', 'w') as f:
json.dump(processed_events, f)
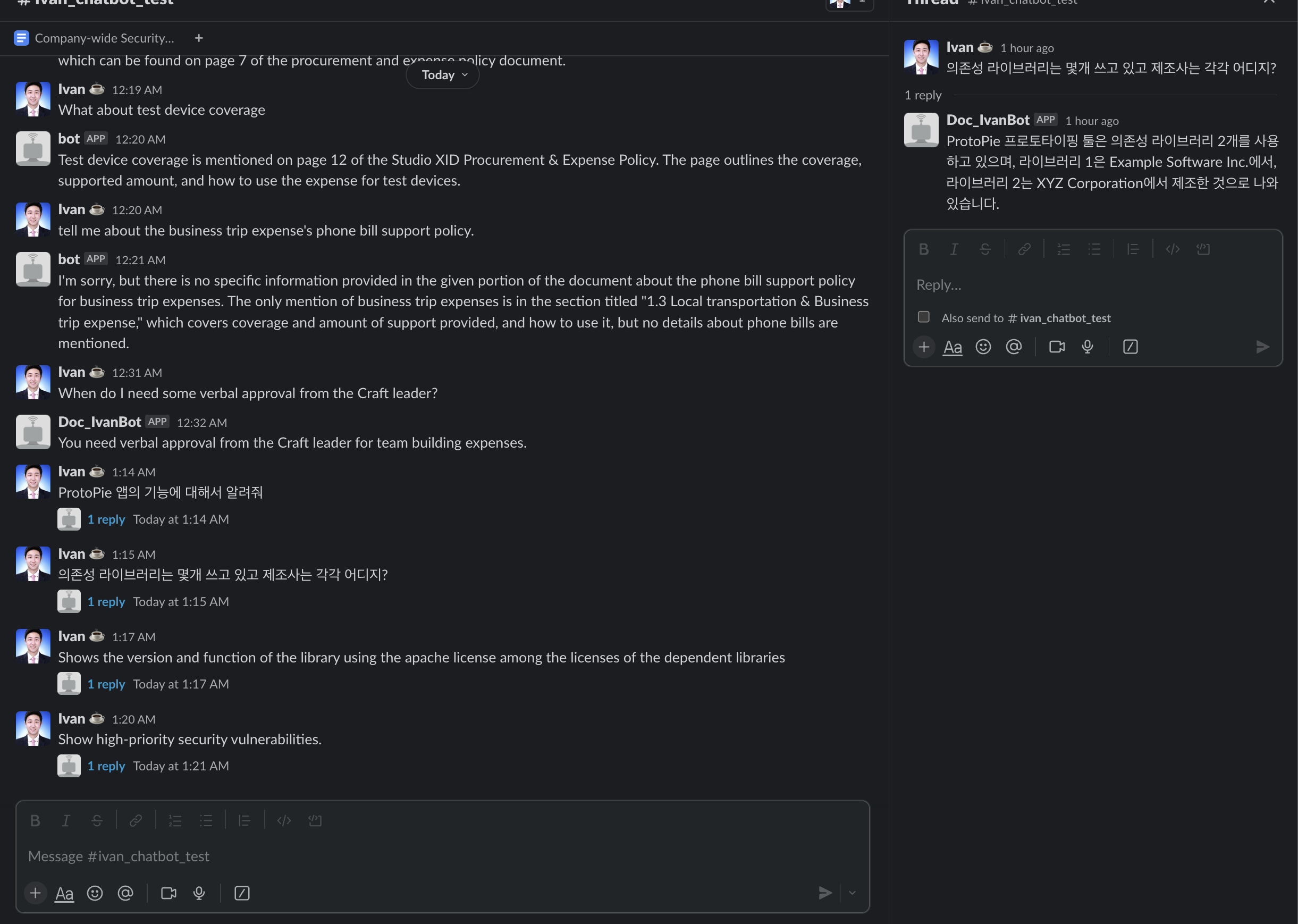
print("Bot got this message from the channel : " + question, "\n/ Thread timestamp : " + str(thread_ts))
# DataFrame 방식일 때
# result = agent.run(question)
#document 방식일 때
result = qa_document_chain.run(input_document=raw_text, question=question)
# 응답을 슬랙 스레드에 전송
try:
response = slack_client.chat_postMessage(
channel=slack_channel,
text=result,
thread_ts=thread_ts,
username="Doc_IvanBot"
)
assert response["ok"]
except SlackApiError as e:
print(f"Error posting message: {e}")
return jsonify({'status': 'success'})
if __name__ == '__main__':
# app 실행
app.run(host='0.0.0.0', port=5005, ssl_context=('cert.pem', 'key.pem'), debug=True)
#
# # 연결 확인 메시지 전송
# try:
# response = slack_client.chat_postMessage(
# channel=slack_channel,
# text="Ivan Bot has been connected!"
# )
# assert response["ok"]
# except SlackApiError as e:
# print(f"Error posting message: {e}")
댓글
댓글 쓰기